Web Crawler - Definisi, Tipe, dan Cara Kerja
Bagi pemilik dan pengembang situs web, pengetahuan tentang web crawler sangat penting dalam mengoptimalkan situs web agar mudah ditemukan dan diindeks oleh mesin pencari.
Praktik SEO sering melibatkan struktur konten, penggunaan tag HTML yang tepat, dan pengelolaan arsitektur situs untuk memudahkan proses crawling. Oleh karena itu, Oleh karena itu, pelajari informasi dasar seputar web crawler berikut ini.
Apa Itu Web Crawler?
Web crawler, juga dikenal sebagai spider atau web bot, adalah program atau skrip otomatis yang secara sistematis menjelajahi internet, menyusuri halaman web, dan mengumpulkan informasi dari halaman tersebut.
Tujuan utama crawler adalah mengindeks dan menyimpan konten situs web agar mesin pencari dapat mengambil dan menampilkan hasil yang relevan kepada pengguna. Biasanya, bot ini memulai penjelajahan dengan serangkaian URL dan kemudian menjelajahi halaman lain dengan mengikuti tautan.
Mesin pencari menggunakan crawler untuk memperbarui indeks mereka, sehingga dapat menampilkan informasi terbaru dari halaman web.
Ketika pengguna memasukkan kueri pencarian, mesin pencari merujuk ke indeksnya untuk memberikan hasil yang relevan dengan cepat. Proses ini bergantung pada web crawler.
Bagaimana Cara Kerja Web Crawler?
Robot crawler bekerja melalui serangkaian langkah sistematis untuk menjelajahi dan mengumpulkan informasi dari internet. Berikut adalah penjelasan lebih rinci tentang cara kerja crawler:
1. URL Awal
Web crawler memulai dengan serangkaian URL awal yang akan dikunjungi. URL ini dapat dikunjungi secara manual maupun secara programatik.
2. Permintaan HTTP
Selanjutnya, crawler mengirimkan permintaan HTTP ke server yang meng-host halaman web di URL awal yang ditentukan. Permintaan tersebut meminta server untuk menyediakan konten HTML dari halaman yang dimaksud.
3. Mengunduh Konten
Setelah menerima respons HTTP dari server, web crawler kemudian akan mengunduh konten HTML dari halaman web. Konten ini mencakup teks, tautan, gambar, dan elemen lain yang ada di halaman.
4. robots.txt
Sebelum menjelajahi sebuah situs web, web crawler memeriksa file robots.txt situs tersebut. File ini berisi aturan yang menentukan halaman atau bagian mana yang tidak boleh di-crawl.
Patuh terhadap aturan ini memastikan bahwa crawler mengikuti preferensi situs web. Selain itu, web crawler mengikuti pendekatan crawling yang tepat untuk menghindari beban berlebihan pada server jika terlalu banyak permintaan dalam waktu singkat.
5. Indeks Konten
Saat crawler mengumpulkan informasi dari halaman web, robot mengindeks konten di dalamnya. Indeksasi melibatkan pembuatan database terstruktur yang memfasilitasi pengambilan informasi dengan cepat.
Mesin pencari menggunakan indeks ini untuk menyediakan hasil pencarian yang akurat dan tepat waktu kepada pengguna.
6. Memperbarui Indeks
Web crawler beroperasi secara terus-menerus untuk menjaga kebaruan konten agar indeks mesin pencari tetap terkini. Sistem akan kembali ke halaman yang sudah di-crawl sebelumnya untuk memeriksa perubahan dan memperbarui indeks.
Jenis-jenis Web Crawler
Web crawler hadir dalam berbagai jenis, masing-masing memiliki fungsionalitas dan tujuan yang berbeda. Berikut adalah beberapa jenis dari web crawler:
1. Generic Web Crawler
Ini adalah jenis web crawler standar yang digunakan oleh mesin pencari untuk mengindeks dan mengkatalogkan konten situs web. Misalnya, Googlebot (digunakan oleh Google), Bingbot (digunakan oleh Bing), Baiduspider (digunakan oleh Baidu), DuckDuckbot (digunakan oleh DuckDuckGo), dan lain-lain.
Crawler ini bertujuan untuk mengindeks berbagai konten di internet sebelum ditampilkan pada hasil pencarian mesin pencari.
2. Focused Crawlers
Berbeda dengan crawler generik, focused atau vertical crawlers dirancang untuk menargetkan jenis konten atau topik tertentu. Sebagai contoh, vertical crawler fokus pada artikel berita, gambar, video, atau kategori konten niche lainnya. Crawler ini sering digunakan oleh mesin pencari khusus.
3. Mobile Web Crawlers
Dengan banyaknya pencarian melalui perangkat seluler, beberapa crawler secara khusus menargetkan situs web versi seluler. Robot ini digunakan untuk memastikan bahwa mesin pencari dapat memberikan hasil relevan bagi pengguna yang mengakses internet melalui smartphone dan tablet.
4. Focused Crawlers for eCommerce
Beberapa crawler dirancang khusus untuk situs web e-commerce dengan tujuan mengindeks informasi produk, harga, dan ketersediaan barang. Crawler ini dapat mendukung mesin pencari dalam menemukan penawaran terbaik.
Itulah beberapa jenis web crawler yang menjelajahi internet untuk mengumpulkan data agar ditampilkan oleh mesin pencari.
Pengaruh Web Crawler pada SEO
Web crawler memiliki dampak signifikan pada SEO karena berkontribusi pada penemuan konten baru di internet. Pasalnya, situs web dengan konten yang baru dan diperbarui secara reguler lebih diprioritaskan oleh mesin pencari.
Crawling juga memastikan bahwa mesin pencari dapat menemukan dan mengindeks halaman-halaman baru, sehingga dapat meningkatkan peluang untuk muncul di hasil pencarian.
Pemilik dan pengembang situs web harus mengoptimalkan situs mereka dengan prinsip crawlability, aksesibilitas, dan relevansi konten untuk memaksimalkan visibilitas di mesin pencari.
Untuk memastikan situs dapat di-crawl, Anda dapat melakukan audit situs menggunakan Sequence Stats Site Auditdan melihat apakah situs Anda mendukung aktivitas web crawling atau tidak. Strategi ini dapat menjadi titik awal untuk memperbaiki masalah. Dengan demikian, Anda dapat menyesuaikannya dengan cepat.
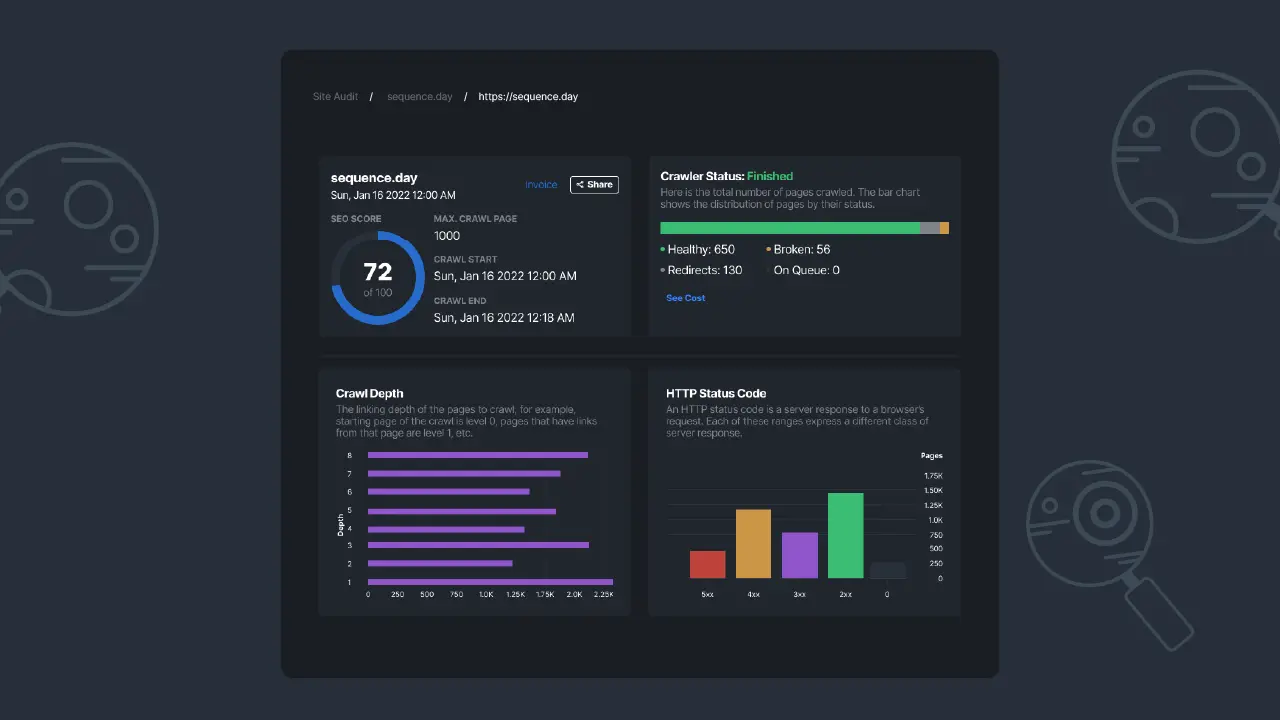 |
|---|
| Gambar 1 - Dasbor Audit Situs dalam Sequence Stats. |
Tidak hanya mengaudit situs, tetapi Anda juga dapat memonitor halaman-halaman yang di-crawl oleh crawler mesin pencari menggunakan Keyword Rank Tracker di Sequence Stats. Di sini, Anda dapat mendapatkan pembaruan peringkat harian dari halaman dan kata kunci Anda. Mengetahui data ini penting untuk mengukur keberhasilan SEO situs web Anda.
| Gambar 2 - Keyword Rank Tracker di Sequence Stats. |
Secara keseluruhan, web crawling penting untuk visibilitas dan SEO situs web. Oleh karena itu, Anda perlu mengoptimalkan situs Anda agar dapat di-crawl dan diindeks. Selain melaksanakan tugas SEO, Anda dapat menggunakan alat bantu untuk menyederhanakan SEO. Daftar ke Sequence Stats dan nikmati uji coba gratis untuk menjelajahi semua fiturnya.