Web Crawler - What It Is, The Types, and How It Works
For website owners and developers, knowledge of web crawlers is crucial for optimizing their websites to be easily discovered and indexed by search engines.
SEO practices often involve structuring content, using proper HTML tags, and managing site architecture to facilitate effective crawling. Thus, understanding web crawlers' basics is important.
What Is A Web Crawler?
A web crawler, also known as a spider or web bot, is an automated program or script that systematically browses the internet, diving web pages and collecting information from them.
The primary purpose of a crawler is to index and save the content of websites so that search engines can retrieve and display relevant results to users. They typically start with a set of seed URLs (initial web addresses) and then explore other pages by following links.
Search engines use crawlers to continuously update their indexes, ensuring that they have the latest information about web pages. When a user enters a search query, the search engine refers to its index to quickly provide relevant results. This process relies on the effective functioning of web crawlers.
How Does A Web Crawler Work?
A web crawler works through a series of systematic steps to browse and collect information from the internet. Here's a more detailed explanation of how a typical crawler operates:
1. Seed URLs
The web crawler starts with a set of seed URLs, which are the initial web addresses it intends to visit. These can be provided manually or generated programmatically.
2. HTTP Requests
The crawler sends HTTP requests to the servers hosting the web pages at the specified seed URLs. The request asks the server to provide the HTML content of the page.
3. Downloading Content
Upon receiving the HTTP response from the server, the web crawler downloads the HTML content of the web page. This content includes the text, links, images, and other elements present on the page.
4. Robots.txt
Before crawling a website, the web crawler checks the site's robots.txt file. This file contains rules that specify which parts of the site should not be crawled. Adhering to these rules ensures that the crawler respects the website's preferences. Additionally, web crawlers follow a polite crawling approach to avoid overloading servers with too many requests in a short time.
5. Content Indexing
As the crawler collects information from web pages, it indexes the content. Indexing involves creating a structured database that facilitates quick retrieval of relevant information. Search engines use this index to provide users with accurate and timely search results.
6. Updating Index
Web crawlers operate continuously to keep search engine indexes up-to-date. They revisit previously crawled pages to check for changes and update the index accordingly.
Types of Web Crawlers
Web crawlers come in various types, each serving different purposes based on their functionalities and goals. Here are some common types of crawlers:
1. Generic Web Crawlers
These are the standard web crawlers used by search engines to index and catalog the content of websites. Examples include Googlebot (used by Google), Bingbot (used by Bing), Baiduspider (used by Baidu), DuckDuckbot (used by DuckDuckGo), and others. These crawlers aim to index a broad range of content on the internet for search engine results.
2. Focused Crawlers
Unlike generic crawlers, focused or vertical crawlers are designed to target specific types of content or topics. For example, a vertical crawler might focus on news articles, images, videos, or any niche content category. These crawlers are often employed by specialized search engines.
3. Mobile Web Crawlers
With the rise of mobile devices, some crawlers specifically target mobile versions of websites. This ensures that search engines can provide relevant results for users accessing the internet via smartphones and tablets.
4. Focused Crawlers for eCommerce
Some crawlers are tailored for eCommerce websites, aiming to index product information, prices, and availability. These crawlers support comparison shopping engines and help consumers find the best deals.
These are some of the web crawler types that surf the internet to gather data for search engines to display.
Web Crawlers Impact on SEO
Web crawlers have a significant impact on SEO; it contributes to discovering new content on the internet. Websites with fresh and regularly updated content are often favored by search engines. Regular crawling ensures that search engines can find and index new pages, improving the chances of visibility in search results.
Website owners and developers should optimize their sites with the principles of crawlability, accessibility, and content relevance in mind to ensure favorable rankings in search engine results.
To ensure that your site is crawlable, you can conduct a site audit using Sequence Stats Site Audit and see whether your site supports web crawling activity or not. This can be a starting point to fix the problem. Thus, you can adjust it quicker.
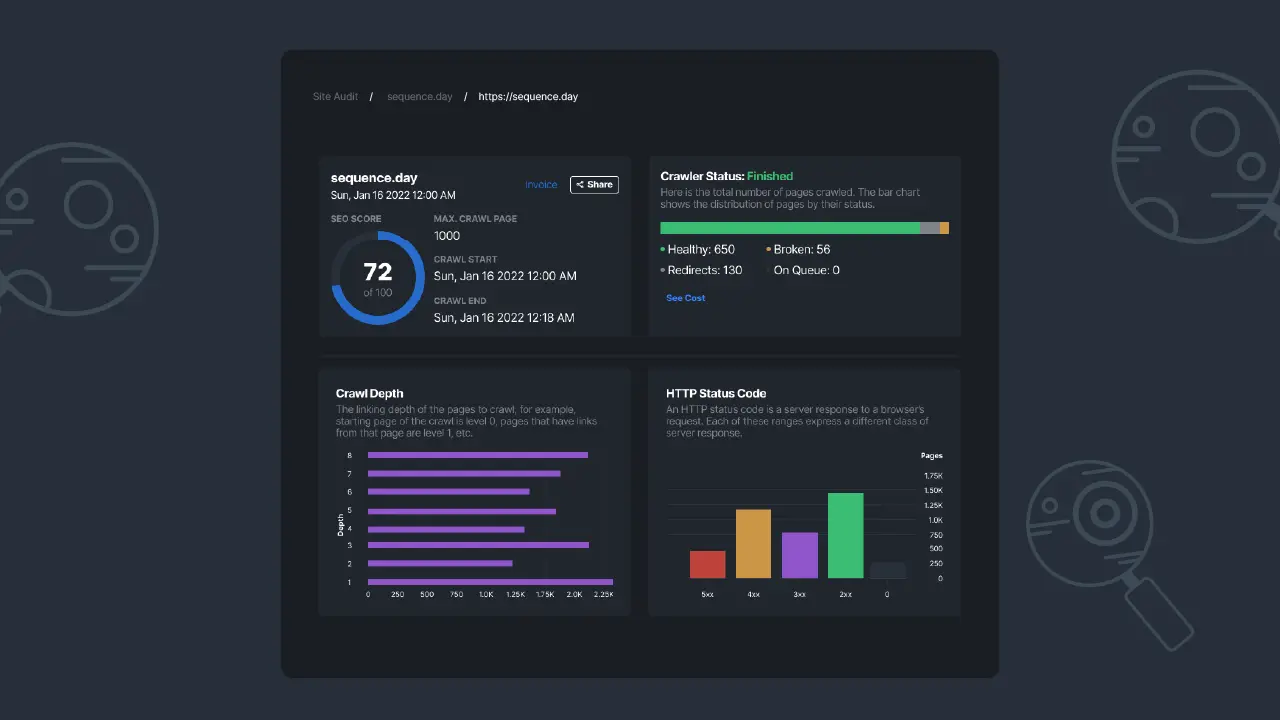 |
|---|
| Picture 1 - Site Audit Dashboard in Sequence Stats. |
Not only auditing your site, but you can monitor the pages crawled by search engine crawlers using Keyword Rank Tracker in Sequence Stats. Here, you can get the daily rank update of your pages and keywords. Knowing this data is important to measure the SEO success of your website.
All in all, web crawling is important for website visibility and SEO. So, you need to optimize your site to be crawlable and indexable. Besides carrying the SEO tasks, you can have a tool as your assistant in simplifying SEO.
| Picture 2 - Keyword Rank Tracker in Sequence Stats. |
Register to Sequence Stats and enjoy the free trial to explore all the features.